
AI & ML Strategy
A robust and coherent strategy with an actionable execution plan increases your chances of succeeding with the development of AI-driven use cases that provide a positive return on investment. Let our experienced advisors help lay out the proper foundations for a meaningful AI journey. Utilising our industry and technical expertise, we can help you identify AI use cases suitable for your business, how to prioritise them and what infrastructure, resources and people you need for their development from POC, through MVP to production. All as part of a coherent, actionable and measurable strategic roadmap.
Step 1
Assess ….AI maturity and readiness to embark on the AI journey. We can assess the AI & Data maturity of your organisation and identify the points for improvement. In this way, we will lay the right foundations for your AI-driven transformation.
Step 2
Prepare … As a transformational technology, AI can have a positive impact on business functions. Our framework helps you to approach it in a strategic way, which is crucial for long-term sustainable returns. Prepare yourself for the journey.
Step 3
Deliver …. Quality and speed of delivery matters. According to a recent study by Gartner, only 22% of organisations claim positive returns on investment from their AI initiatives. Furthermore, even fewer companies manage to reach enterprise-wide successful AI-adoption in production. Get in touch with us and let’s discuss how we can help you avoid the pitfalls throughout this journey.
Step 4
Maintain … Maintain, adapt and evolve. Both internal and external factors play a role in the performance of your company. This is reflected in the data you use for your models. It also affects your business needs and operational processes. The same applies to the AI-driven model you will have in production. It needs constant monitoring, feature engineering and performance parameters tuning in order to keep its accuracy, latency, and throughput at the expected levels. All this needs to happen at the right pace and at the lowest possible cost to you. In order for this to be achievable, the foundations of your AI strategy are crucial.
AI Development
Have an idea but not sure where to start with its development? Or maybe you’ve started but are unsure of how to scale? We can help. We’ve created a framework which can help you throughout all phases of your AI journey, from ideation to POC, MVP and scalable production. Our team of Data Scientists, ML Engineers, Data Engineers and DevOps Engineers have already worked alongside our clients’ domain experts. We can work together to develop a first-class AI-driven application, which is tailored to your business needs.
Sounds familiar to your challenges with AI? Find out more about our capabilities and what we’re good at.
According to Gartner, four out of five AI and machine learning projects fail to deliver while half of all projects make it from prototype to production. Why is this the case?
How do we characterise a first-class AI solution? A robust and profitable AI solution must be measurable, predictable and cost-controlled in terms of software development and performance assurance. Furthermore, we make sure that the outputs of the algorithms are well-integrated securely and safely into the processes of your organisation, ensuring proper usability of the generated insights from the AI products.
What are we good at?
Forecasting models
Recommendation systems
Natural Language Processing
Computer vision
Sophisticated data analysis
Classification and clustering models
Optimisation systems
Predictive models
Prescriptive models
AI Operations
Now that you have a working prototype or an AI solution in production you need to maintain, evolve and scale. We can help. We work alongside you and help you orchestrate and deploy an integrated state-of-the-art AI solution. Trust us in operating and monitoring your data and AI pipelines, avoiding any downtime to the highest degree of reliability.
It’s easy to underestimate the step between the POC solution, developed by the data scientists, and a fully-functioning, productionised AI solution. This is where most companies struggle. The business value for your organisation will derive once the models are fed with real-time or near real-time data, depending on the business requirements, and the outcomes of the models are fully integrated into your existing processes.
AI & ML Case Studies

Point of View: Opportunities for AI adoption in Banking
Increased CLV through a personalised customer-centric approach.
Executive summary
Traditional banks face several challenges in the modern banking landscape. These challenges arise due to the changing expectations of customers and the rapid advancements in technology.
To address these, banks must embrace innovation, invest in technology and talent, prioritize cybersecurity, and maintain a customer-centric approach while navigating regulatory requirements.
All-encompassing strategy formulation and adaptable, coherent execution are key to thriving in the dynamic banking landscape.
The important questions
- How likely is the client to purchase a product?
- How profitable is it to approach a customer with a specific offer?
- How to increase cross-sell and up-sell?
- How can we improve response rates to direct marketing campaigns?
- How to transform each contact into a sales opportunity?
Challenge description
There is a trade-off of the goals between the Marketing and Sales and Risk Departments.
Risk Department is incentivized to keep the risk levels low and to avoid customers with higher chances of default.
Marketing and Sales Department on the other hand, benefits from higher number of high-end products sold. This leaves out:
- Willing clients that are deemed risky by the Risk Department (only based on Risk features);
- Clients that are accepted by the Risk Department but are deemed to be non-interested by the CRM (only based on CRM models)
The customer lifecycle view
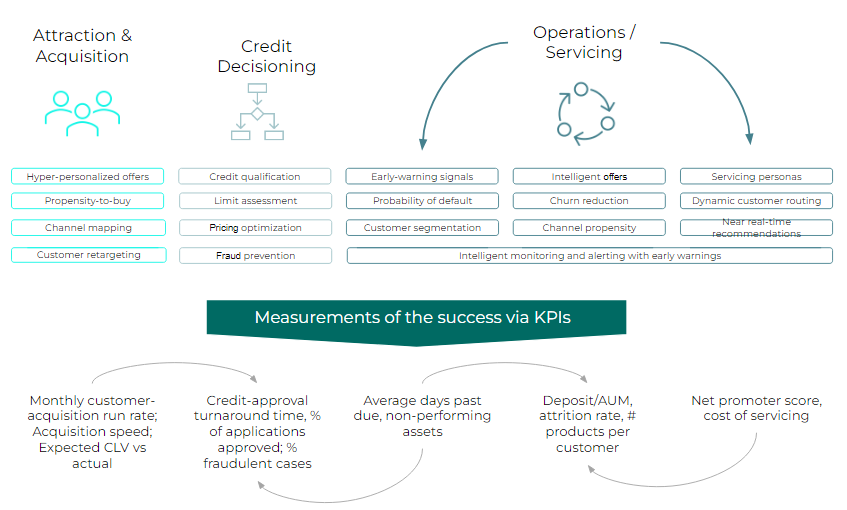
How is it done?
-
Customer Lifetime Value
All steps listed below, when executed in combination lead to a higher CLV with an increased NFI.
-
Personalised offering, Next Best Action, Personalised Marketing
The Next Best Action algorithm is used to predict the best ways and times to deliver enhanced customer satisfaction resulting into higher campaign response rate and deal closures. As an additional step, algorithms for personalized offerings can be incorporated into the system.
-
Next Best Offer
NBO increases revenue by predicting the most relevant products or services and up-sell/co-sell opportunities to individual customers.
-
Net Financial Impact
The models maximize the Net Financial Impact obtainable from the customers meanwhile considering the applicable risk limits.
-
Propensity to buy, Probability of Default, Expected Loss, Expected Profit, Customer Churn, Fraud Detection, and Customer Segmentation
PtB models enable the expansion and optimization of credit portfolios in competitive and saturated markets by calculating the likelihood, that customer will buy a product or a service. The solution takes into consideration further inputs and constraints.
PtB-driven solution
Current state

The traditional lending process
The traditional preapproved credit sales process consists of two steps:
- setting the preapproved limit by the Credit Risk department
- targeting the offers by the Sales/Marketing department
This approach leads to two thresholds.
Future state

Suggested approach
Considers simultaneously information from both the Sales/Marketing and Risk departments. This allows for customer targeting by risk-adjusted expected profit, thus increasing the overall profitability and size of the credit portfolio over its lifecycle.
What are the benefits of the suggested approach?
- Higher Net Financial Impact (NFI) for the bank
- Prolonged Customer Lifetime Value (CLV)
- Enhanced Customer Experience
- Improved Efficiency and Productivity
- Data-Driven Insights and Decision Making
- Regulatory Compliance
- Personalized Marketing
- Automatization of Loan Application & Approval Process
Outcomes: Banking products suggestions, driven by technology can help scale the business while lowering costs at the same time.
If you are looking for the right AI solution, get in touch with our team to help you find the best resolution for your organisation’s needs.

AI model development and certification for cardiovascular medicine
Overview: Our client is a European MedTech start-up focused on the detection of cardiovascular anomalies. The start-up’s objective is to challenge the market for ECG signal-based detection of heart pathologies, such as, but not limited to, atrial fibrillation, premature beats, subventricular tachycardia, etc, obtained from affordable wearable devices such as the Polar H10. The company required an ML-based model development and preparation for the Class 2A medical device certification, in order to ensure that their system is safe and effective for patients to use at home.
Team: Our team of experts included a Data Engineer, Data Scientists, ML Engineers and a Project Manager
Approach:
Discovery phase
Our Data Scientists collaborated with the client in order to understand their existing ECG signal processing system, as well as their computation-based algorithms. We created an automated testing tool that assessed the performance of the current solution against a range of internal and external medical data sets. Based on this analysis, we provided recommendations to improve the scope of detectable medical conditions and identified areas for improvement.
We advised the client on the certification process and prepared an action plan for the ML-related work and documentation needed for the Class 2A certification. We also provided improvement recommendations and execution support, which helped the client enhance their ECG signal processing system and algorithms. Our team completed the analysis and recommendations in less than 8 weeks, providing actionable advice, which helped the client reduce the application processing time.
ML-based signal processing model development phase
The client provided the raw ECG signal data, including labelled data with annotations of R-peaks, pathologies, as well as ‘soft’ and ‘hard’ noise segments. This labelled data was used as inputs for the models and deemed as their training set. The quality and accuracy of pathology predictions (detection) heavily depend on the cleaness of the ECG signal. This is why it is important to have robust, well-performing models in terms of accuracy and precision, which can distinguish between the clean and noisy parts of the ECG signals. Our Data Scientists developed ML-based models for ‘soft’ and ‘hard’ noise detection. Upon successfully passing the strict model performance acceptance criteria of the client, our ML Engineers created the production pipelines for training and inference and integrated it into the client’s platform and business processes. Our collaboration continues with the development of further pathology detection ML-based algorithms.
Results: Through our active collaboration with the client's team, we were able to complete the model certification preparation work in just 6 months, helping the client achieve their goal of obtaining a Class 2A certification for their AI-powered medical device system. This certification allows the client to offer their product to a wider range of customers, enabling them to provide early detection and prevention of heart-related medical conditions.

Video platform and chatbot for historical education museum
Overview: The Client was in need of our expertise to develop an interactive online platform for historical education centred around the survival stories of prisoners in the concentration camps during the Communist era in Bulgaria. The general idea was to allow the users to have a virtual video conversation with the survivors by asking questions and receiving the
best answer from a pre-recorded set of answers to the most popular questions. They had drawn inspiration from a similar project about stories from Nazi-Germany concentration camps, but they didn't have the technical know-how on how to achieve it. A similar platform can be seen here. We worked in cooperation with multiple teams engaged with filming the interviews, video processing and graphic design.
Solution:
Phase 1 - Planning
We started with thorough planning of the questions for the interviews and the recording process since the team had only a couple of days to spend with each person and there was no room for mistakes. Every person had to be interviewed according to a prepared script and asked a very specific list of more than 500 questions such as "What is your name?", "What is your favourite colour?", "What do you remember about World War II?" and others.
Phase 2 - Data preparation
The video post-processing team took the challenging task to cut and edit the raw videos into a set of several thousand video answers. Our job was to categorize all of the video data by a weighted keywords approach and implement an algorithm that would match the keywords in the user question with the categorized answers in the database.
Phase 3: Algorithm development
Taking into account the grammar specifics for the English and Bulgarian languages, we made several configuration iterations to adjust the weights of the keywords and improve the performance of the algorithm. A team of internal and external testers helped to verify the results by trying out a large number of questions with different wording variations. All of the tests were monitored and actively used to constantly improve the algorithm.
Once the platform recorded enough real-user data, the plan was to introduce an AI language model to allow for even more realistic and insightful conversations with the survivors. We would still use the keyword-matching algorithm to compare and measure the AI model performance, which would need significantly more data than we initially had at the start of the project.
Phase 4 - Website development
When the algorithm was ready we continued with integrating it into the rest of the platform where users can log in, keep track of previous chat sessions and find out interesting information and facts about that particular historical period for further evaluation.
Future plans: Once the platform records enough real-user data, an advanced AI language model will be introduced to allow for even more realistic and insightful conversations with the survivors. The weighted keyword-matching algorithm is a good benchmark to compare and measure the AI model performance, which would need significantly more data than we initially had at the start of the project.

A CRM model for effective customer offer optimization in retail banking
Overview: A retail bank faced the challenge of optimizing offers to attract new clients and upsell existing clients. The marketing and risk departments were working with different approaches, and there was a need for a unified score that could provide a single measure of expected profitability per client. To address this challenge, our data science team was tasked with developing an AI solution that produces a robust objective score for the expected profitability per client, based on both marketing and risk factors.
Solution: Our team developed a CRM (Customer Relationship Management) model that combines marketing and risk factors to evaluate the expected profitability of each banking product based on our developed methodology product. The model uses Propensity-to-Buy (PtB) models to predict the likelihood of a customer purchasing a specific product, and Probability of Default (PD) models to estimate the risk of the customer defaulting on a loan. The output of the model is a single measure of expected profitability per client, which can be used to rank the Next-Best-Offer (NBO) for each customer.
To develop the CRM model, we first collected and integrated data from various sources, including transactional data, demographic data, and customer interaction data. We then applied various machine learning algorithms, such as logistic regression and random forests, to train and test the PtB and PD models. We also conducted feature engineering and selection to identify the most relevant variables for predicting profitability.
Results: The CRM model was tested in a champion-challenger setting, where a control group received NBOs based on business rules, while a test group received NBOs generated by the CRM model. The response rate (up-sell) in the test group was five times higher than in the control group, indicating that the CRM model was more effective at identifying profitable offers for customers.
The CRM model has been deployed in production and is now being used to optimize customer offers in real-time, based on the most up-to-date customer information. This has resulted in increased profitability for the bank and a better customer experience, as customers are offered products that are more relevant to their needs and preferences.
Empowering athletes: crafting success with the Sika Strength App
Overview:
Sika Strength, a cutting-edge health, and lifestyle company, aimed to enhance athletes' performance. Specialising in tailored training programs, they sought a technology partner to build an app that could empower athletes to excel. Sika Strength's team was knowledgeable and throughout the whole process contributed with domain knowledge, including insights into fitness training methodologies, exercise routines, and user preferences, enriching the app with authentic and effective training content.
Challenges:
A primary challenge was creating an app that is robust, and scalable, incorporating an AI-driven chatbot with no hallucinations while delivering an interactive, user-centric experience. The mutual inspiration between the teams catalysed creativity and dedication.
Solution:
CHILDISH.AI's dedicated team crafted the entire app, featuring advanced functionalities and an interactive chatbot powered by generative AI. The model leverages trained data to analyse datasets, proposing optimal responses. The chatbot streamlines customer support, enriching the user experience. Together, we've sculpted a seamless, intelligent training companion, harmonising CHILDISH.AI's technological prowess with Sika Strength's dedication to healthy living and sports.
Team: UX designer, front-end Developers (React & React Native), back-end Developers (Python & Django), Data Scientists, Solution Architect, QA, and Project Manager.
Results: The Sika Strength App is born—a seamless, intelligent training companion offering a comprehensive library of weightlifting programs and exercises, complemented by video tutorials.
User-Favourite Functionalities: Users can personalise workouts, with the app calculating training frequency and weight for optimal fitness levels. The interactive chatbot, powered by generative AI, enhances the overall user experience.
1000 Active Users in < 6 Months: The collaborative effort resulted in rapid success—with almost 1000 active users within six months. This is a testament to the success of the partnership between CHILDISH.AI and Sika Strength.

NLP development for a pharmaceutical company
Challenge: The client, a multinational pharmaceutical company wanted to refactor an existing system for enquiry management and improve its performance and analytical capabilities through AI. The goal was to ensure a consistent customer experience across multiple locations.
Industry: Healthcare
Approach: Our team used semantic analysis with NLTK preprocessing to create different feature extraction and drug product labelling over already accumulated and classified еnquiry data. Preprocessed data were used to train Keras with the TF engine, and evaluated versus built-in SVM algorithms in SKLearn. Results were accuracy near 80% for classification. ML components were integrated into the auto-assign pipeline based on product and team recognized in free text еnquiry.
From a business perspective, the complete solution speeds up the process of enquiry management and contributes to overall customer satisfaction and increased operational efficiency.
Tech stack: Python and Angular developers, Data Scientists, ML Engineers, Project Manager.
Results: Successful completion of refactoring tasks and introduction of the NLP module. The achieved results were near 80% accuracy for the classification of enquiries.

AI screening tool for a recruitment software
Overview: The client was a start-up solving the problem of managing numerous processes within a recruitment department. Hiring teams have data from a variety of sources, which are difficult to process and analyze. Our task was to structure and develop a data structure and create an AI tool for screening candidates.
Approach: Our team of data engineers, data scientists, and ML engineers started with a research phase to understand the client's requirements and identify the best approach for the project. We conducted a thorough analysis of the recruitment data landscape and the different types of data sources used in the industry. We then developed a solution architecture that could handle the complex data structures and AI models required for the project. We selected AWS as the primary provider for data storage and combined it with other ETL tools to work with different formats from multiple sources.
Once the data structure and pipelines were set up, we used semantic analysis with NLTK preprocessing to extract the necessary information for each candidate. The semantic analysis allowed us to identify the candidate's skills, experience, and education from their resume, cover letter, and social media profiles. We then developed the ML model using Keras, TensorFlow, and SKLearn to sort the candidates into predefined groups and factors, such as experience level, job title, and location. The output was presented in a structured database of candidates, which could be easily searched and filtered by hiring teams.
Key Metrics: The AI screening tool provided significant benefits for our client's recruitment process. The applicants in the system were automatically shortlisted, and the hiring teams only needed to review the screening results.
The solutions achieved their goal of optimizing the time a recruitment team needs for manual review of the CVs of candidates and reducing it by half. The increased productivity allowed them to focus on more strategic tasks, such as conducting interviews and assessing candidate fit.
Software with computer vision analysis in a manufacturing plant
Challenge: The task was to develop a solution for task management in production companies combined with extracting data from production machines through sensors and PLCs.
Team: Python developers, Angular developers, Data scientists, Computer vision experts, QA experts, DevOps, UX designer and PM
Solution: The solution was successfully developed for the MVP phase and continued to include computer vision combined with tasks, procedures and read-only registers from PLC controllers. Currently using Python OpenCV & YOLO object detector integration from IP camera stream to extract workers' movements around specific industrial areas. We collect data first to perform supervised learning in later stages.
Status: Currently, the software is being integrated into 3 production plants in Bulgaria.
Key Metrics: Reduction of maintenance costs by more than 20% within a period of 1 year.

Image recognition and NLP for fraud detection
Challenge: Creating a fully functioning solution from scratch
Team: Data Engineers, Data Scientists, ML Engineers, DevOps
Solution: The project started with the investigation phase to analyse the existing data and test multiple solutions which meet the needs of both client and cloud providers. AWS was selected as a core service provider for data storage combined with ElasticSearch. Our team built the full ETL process to start operations. Once the data structure and pipelines were set, we introduced two teams of Data Scientists - one specialized in semantic analysis (NLP) and the other with experience in image recognition. The ML part was further taken care of by our engineers. The output was a dashboard of data visualisations made in Kibana to present the results.
Status: Successful completion of the data engineering phase with ongoing data science stages.
Results: The project significantly improved the client's ability to detect security breaches behaviour, which led to a reduction in risk.

Traffic analysis and prediction based on AI
Challenge: The client`s request involved road and traffic analysis. The task included building a vehicle counting system based on vehicle type and classification, as well as differentiating between various types of vehicles and conducting a total count.
Approach: We started by developing a custom video surveillance software which made it possible to remotely watch the traffic situation and collect data. Utilizing image recognition and data analytics techniques we developed a POC model analysing the traffic data, which was further extended to a fully functioning tool for road and safety as the traffic analysis.
Through advanced deep learning our team created a solution which was able to detect and alert for potential accidents, predict congestion, or plan efficient roads and parking spaces. The solution is currently growing into autonomously monitoring traffic cameras and systems and generating real-time alerts when certain events of interest occur.
Tech stack: Python, React.JS, Yolo, SSD and OpenCV
Results: The solution enables easy supervision of key crossings, risk spots and motorways with the goal to reduce and prevent accidents.
The solution provides remote supervision of the movement of motor vehicles on streets and motorway crossings which helps in easy monitoring of on-location visits.
Developing a comprehensive PD model for accurate credit risk assessment in banking
Overview: The banking industry faces a significant challenge in accurately assessing the creditworthiness of borrowers to make informed lending decisions. Traditional credit scoring models, which often rely on limited information such as credit history, may not accurately reflect the risk of default. To address this challenge, our team was tasked with developing a more accurate and comprehensive model for predicting the probability of default.
Solution: Our team developed a PD (Probability of Default) model that uses a wide range of customer data, including behavioural and demographic data, to predict the probability of default. The model is based on machine learning algorithms that are trained on historical data to identify patterns and correlations between different variables and default risk.
We first collected and cleaned a large dataset of loan applications and associated customer data and used various machine learning algorithms, such as logistic regression and decision trees, to train and test the model. We also conducted feature selection and engineering to identify the most relevant variables for predicting default risk.
The output of the model is a single score that reflects the probability of default, which can be used to inform lending decisions and set appropriate interest rates.
Results: The PD model was tested on a dataset of loan applications and compared to traditional credit scoring models. The results showed that our PD model outperformed the traditional models in terms of predictive accuracy and ability to identify high-risk borrowers. The model was subsequently deployed in production and has been used to inform lending decisions and set interest rates for loan products.

Federated Learning for personalized healthcare prediction models in oncology
Challenge: Between 2009 and 2013, our Head of Data Science led the AI development and implementation of the euroCat project, a groundbreaking solution for personalized treatment methodology in radiation oncology. The project involved five hospitals across three EU countries, utilizing the data of their cancer patients with the aim to optimize personalized treatments. The goal was to develop a Machine Learning model that is capable of learning from disparate data sources without centralizing patient data, in a way that preserves patient privacy. You can read more about euroCat in the academic paper.
Solution: The solution leveraged Federated Learning (which has become the more common name for distributed learning) - a technique that enables multiple parties to collaborate on a Machine Learning model without sharing sensitive data and without the need for data to be centralized, via exchanging only model parameters during the learning process.
In this approach, each hospital trains part of the model at each iteration using its local data and then shares only some parameters with a central server. The central server then aggregates the parameters from all countries to update the global model without accessing the local data. The learning continues through iteration cycles until model convergence criteria are met. The role of a “central server” can be played by any of the hospitals on the grid. Georgi Nalbantov’s AI team used Federated Learning to learn Support Vector Machine (SVM) models, using the Alternating Direction Method of Multipliers (ADMM), from disparate databases to predict treatment outcomes: which can be either a direct treatment effect or a treatment side effect, for example, shortness of breath after (lung) radiotherapy.
The performance of the SVM models was evaluated by the Area Under the Curve (AUC) in a five-fold cross-validation procedure (training at four sites and validation at the fifth). The performance of the pooled (federated) learning algorithm was compared with centralized learning, in which the datasets of all clinics are combined in a single dataset. The result of the centralized model was (naturally) the same as the federated-learning model, as they are mathematically yielding the same result.
The euroCat project using Federated Learning had a significant impact on the development of personalized medicine in radiation oncology. It demonstrated that it is possible to collaborate on a machine-learning model without sharing sensitive data, while still obtaining results that are the same as those achieved through centralized learning. Moreover, the project's approach enabled better and more personalized treatments for cancer patients, as the machine-learning models were trained on a combination of datasets that represented the variations across the entire population of cancer patients from these (five) hospitals.
The solution is used in several clinics across Europe. However, the methodology is applicable in other sectors where sharing data between independent parties is not an option like healthcare, banking and insurance.
Research Overview: Cardiac Comorbidity and Radiation-Induced Lung Toxicity (RILT)
Research led by Georgi Nalbantov PhD, Head of Data Science @ Childish.AI, to examine the impact of pre-existing cardiac conditions on radiation-induced lung toxicity (RILT) after high-dose radio(chemo)therapy for lung cancer.
Overview:
- Traditionally, radiation effect on the heart and lungs were studied separately
- Recent studies reveal a short-term interaction between heart irradiation and lung dysfunction
- This study bridges the gap by investigating how cardiac issues affect RILT in the short term
Observations:
- 28.9% of patients had cardiac comorbidity before radiotherapy
- 44% of patients had cardiac comorbidity before radiotherapy
- Patients with cardiac comorbidity had 2.58 times higher odds of developing RILT
Predictive model for RILT:
- A model was built which helps identify patients at higher risk of RILT
- This model incorporates cardiac comorbidity, tumour location, lung function, chemotherapy, and pretreatment dyspnea score
- The model demonstrated an Area Under the Curve (AUC) of 0.72 in the training set and 0.67 in the validation set, signifying its predictive performance
Key implications:
- Cardiac comorbidity contributes significantly to RILT cases
- Tailored treatment approaches are essential for patients with cardiac comorbidity
- Excluding these patients from dose escalation studies may optimize outcomes
Let's work together